
varCHAR
varCHAR is an AI-driven, unified data pipeline platform engineered on top of Apache Spark, Kafka, and Camel. It empowers organizations to streamline complex data flows and achieve real-time analytics with intelligent processing capabilities.

About varCHAR
varCHAR: Revolutionizing Data Pipelines with AI and Open Source Power
In the rapidly evolving landscape of big data, the ability to move, process, and analyze information in real-time is the defining factor for enterprise success. varCHAR enters the market as a sophisticated, AI-driven unified data pipeline platform, expertly designed to handle the complexities of modern data architecture. By leveraging the robust capabilities of Apache Spark, Kafka, and Apache Camel, varCHAR offers a seamless, integrated environment for data engineers and developers.
The Core of Intelligent Data Processing
At its heart, varCHAR is more than just a connector; it is an intelligent ecosystem. By integrating a dedicated Kafka platform with the processing speed of Spark and the integration patterns of Camel, it solves the fragmentation often found in traditional ETL processes.
Key Features:
- AI-Driven Optimization: Utilizes artificial intelligence to monitor data health, predict bottlenecks, and optimize pipeline performance automatically.
- Unified Architecture: Consolidates batch and streaming data into a single, manageable interface, reducing infrastructure overhead.
- Robust Integration: Powered by Apache Camel, it connects effortlessly to hundreds of endpoints, ensuring no data silo is left behind.
- Scalability & Speed: With Apache Spark and Kafka under the hood, varCHAR ensures high-throughput, low-latency processing suitable for enterprise-grade workloads.
Empowering Data Teams
varCHAR reduces the boilerplate code usually required to stitch these technologies together. Whether you are building real-time fraud detection systems, synchronizing databases across cloud environments, or feeding data lakes for machine learning models, varCHAR provides the stable, intelligent backbone required. It transforms raw data chaos into structured, actionable insights, making it an essential tool for technology-forward organizations looking to modernize their data stack.
Tags
Similar Tools
View all items →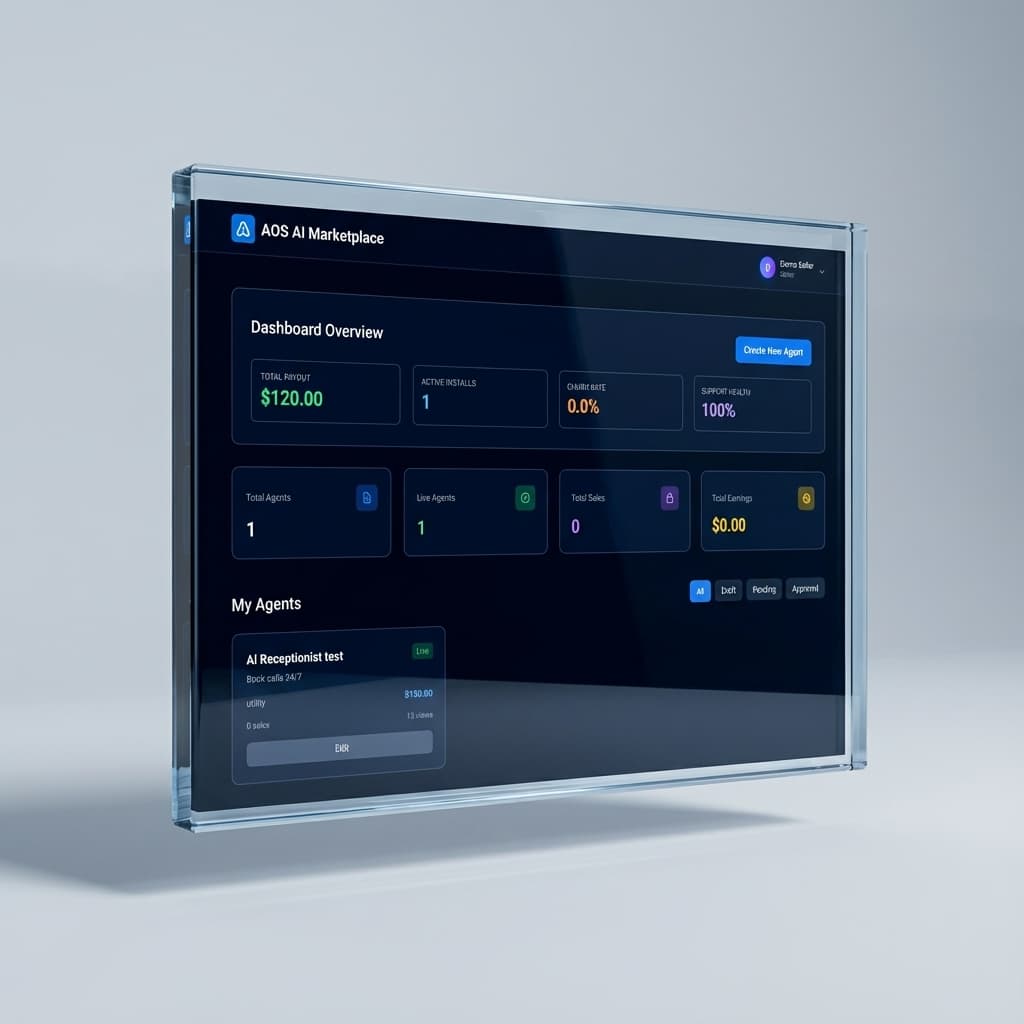

AOS Ai Marketplace
AOS Ai Marketplace offers a curated selection of vetted AI agents designed to instantly qualify leads and book meetings. Recover lost revenue and automate your inbound sales process with proven digital workers that deliver tangible results.


Context
Context acts as your dedicated AI meeting companion, ensuring you never lose track of crucial conversation details. With intelligent pre-meeting briefings, it helps you effortlessly recall every interaction and fact about your contacts.


GitHub
SilentKeys is a privacy-first, offline dictation tool for macOS that utilizes Parakeet models to transcribe voice to text directly on your device. Powered by a high-performance Rust engine, it delivers real-time accuracy without cloud dependency or data telemetry.